Top 10 ETL Testing Tools to Watch in 2020
ETL Testing has a lot of demand in the market all the time. ETL Testers are paid better than Manual/ Functional ones. So, those who are interested in Database /SQL and want to upgrade themselves in a career should definitely learn ETL Testing Tools.
Here we have provided Top 10 ETL Testing Tools with its features to check. You need to decide which ETL Tool you can choose, based on your requirements or which one your organization or client is using.
Please check our SQL Tutrials specially designed for Testers
What is ETL?
ETL is a type of data integration that refers to the three steps (Extract, Transform and Load) used to blend data from multiple sources. It’s often used to build a Data warehouse. During this process, data is taken (extracted) from a source system, converted (transformed) into a format that can be analyzed, and stored (loaded) into a data warehouse or other system.
- Extract: – This is the process of reading data from a database. In this stage, the data is collected, often from multiple and different types of sources. The data can be in various formats like relational databases, No SQL, XML or Flat files
- Transformation: – This is the process of converting the extracted data from its previous form into the form it needs to be in so that it can be placed into another database. Transformation occurs by using rules or lookup tables or by combining the data with other data.
- Load: – The third and final step of the ETL process is loading. In this step, the transformed data is finally loaded into the data warehouse.
Sometimes the data is updated by loading into the data warehouse very frequently and sometimes it is done after longer but regular intervals.
The target may be Data warehouse or data mart.
Top ETL tools:
- Informatica PowerCenter
- Abinitio
- DataStage
- SQL Server Integration Services
- DMExpress
- Pentaho Data Integration
- Talend
- AWS Glue
- Xplenty
- Aloom
1. Informatica PowerCenter

Informatica PowerCenter developed by Informatica Corporation. It supports the entire data integration lifecycle addresses data integration initiatives, along with commercial enterprise intelligence, data warehousing, data migration, and cloud application integration. It also can be used for big data integration, data cleansing, and master data management. This tool will extract data from different data sources, transforms through different intermediate systems and then loads on a target system.
Key Features:
- Customers gain from graphical and code-less tools that leverage an entire palette of pre-constructed transformations.
- PowerCenter repository which resides in a relational database. They are the tables that contain the instructions to extract, transform, and load data.
- Function-based equipment and agile processes enabling business self-carrier and delivery of well-timed, depended on information to the enterprise.
- Connectivity and transformations that work with numerous source and target structures.
- Reusability, automation, and ease of use.
- Scalability, performance, and zero downtime.
- A repository that captures, displays and administers process and design metadata.
- PowerCenter makes use of real-time information for application and analytics.
- Analysts can collaborate with IT to hastily prototype and validate results fast and iteratively.
- Integration of data from all kinds of assets, the usage of high-overall performance, out-of-the-container connectors.
- Data validation testing out through automation.
- Advanced data transformation like unlock the value of non-relational data by comprehensive parsing of XML, JSON, PDF, Microsoft Office, and Internet of Things machine data.
- Advanced statistics transformation like liberating the cost of non-relational statistics with the aid of comprehensive parsing of XML, JSON, pdf, MS-Office and machine data.
- Last but not least it is compatible with cloud connectivity.
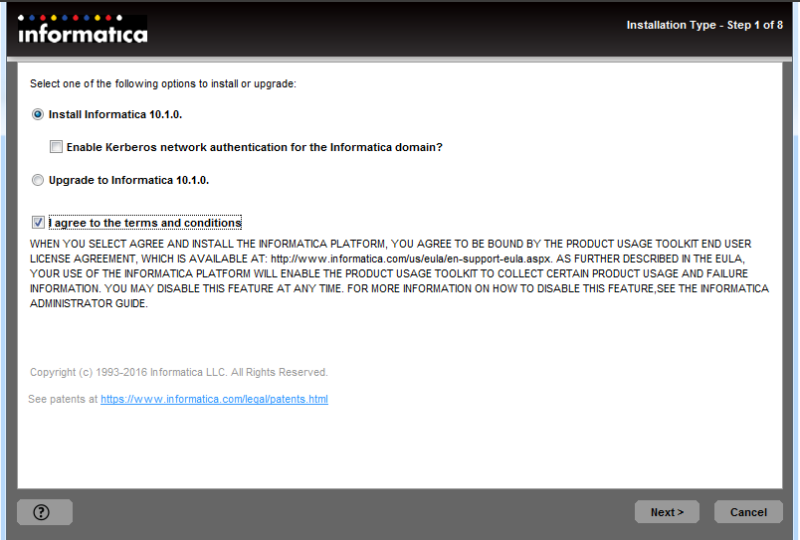
Informatica Installation screens:

2. Ab Initio
![]()
Ab Initio has a single architecture for processing files, database tables, message queues, web services, and metadata. This identical architecture permits virtually any technical or business rule to be graphically defined, shared and accomplished. It processes data in parallel across multiple processors, even processors on different servers. Ab Initio could run the identical rules in batch, actual-time, and within an SOA (service-oriented architecture). It helps disbursed checkpoint restart with application monitoring and alerting. And, this same architecture permits end-to-end metadata to be accumulated, versioned and analyzed by non-technical user
Key Features:
- A single tool for all factors of utility execution.
- Metadata capture, analysis, and display.
- Data management, inclusive of very large data storage (hundreds of terabytes to petabytes), data discovery, evaluation, quality, and masking.
- Business policies for all factors of utility execution.
- It supports Windows, Unix, Linux and Mainframe platforms.
- Potential to run, debug Ab initio jobs and trace execution logs.
- Effortlessly put into effect the enterprise regulations via advanced capabilities like ACE/BRE without the intervention of the developers.
- Ab Initio programs are represented as “dataflow graphs,” or “graphs”.
- This Tool Library is a reusable software module for sorting, data transformation, and high-speed database loading and unloading.
- Data quality design pattern is based totally on a set of powerful, reusable building blocks.
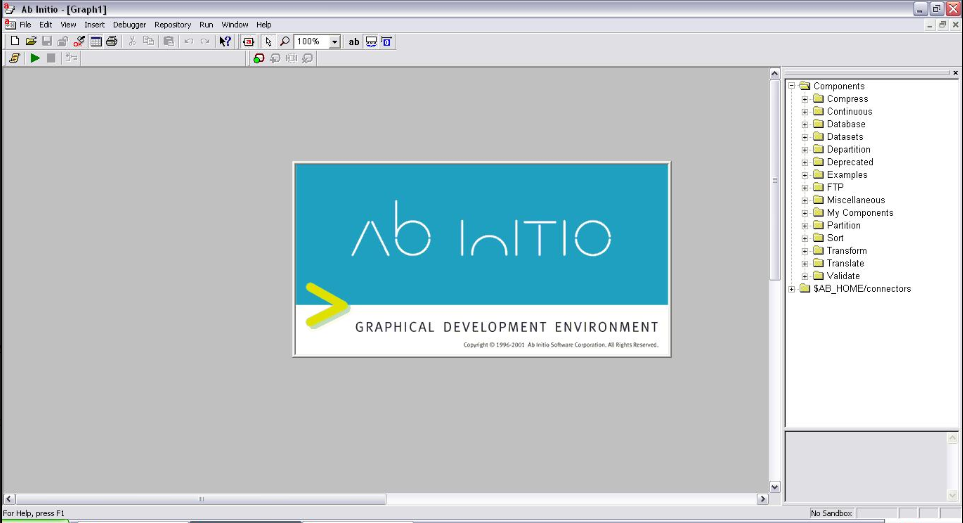
Screenshot:
3. DataStage:
![]()
IBM InfoSphere DataStage is an industry leader in ETL and affords a multi-cloud platform that integrates data across multiple enterprise systems. This tool will allow business analysis by way of presenting quality data to help in gaining business intelligence.
Key Features:
- Great ETL platform, acquire data, integrate data and transform big volumes of data, with data structures ranging from the easy to the complex.
- It’s easy and fast deployment of integration runtimes on-premises or across multiple cloud systems.
- Different kind of data stage jobs consists of Parallel job, Server job, Job sequence.
- prolonged metadata management and enterprise connectivity.
- Integration of heterogeneous records, which includes big data at rest (Hadoop-based) or big data in motion (stream-based), on each dispensed and mainframe platforms.
- This tool will hook up with a couple of sources and targets at the same time.
- User-friendly design and development capabilities.
- Agile architecture.
- It offers a development cycle, the usage of design automation and prebuilt patterns.
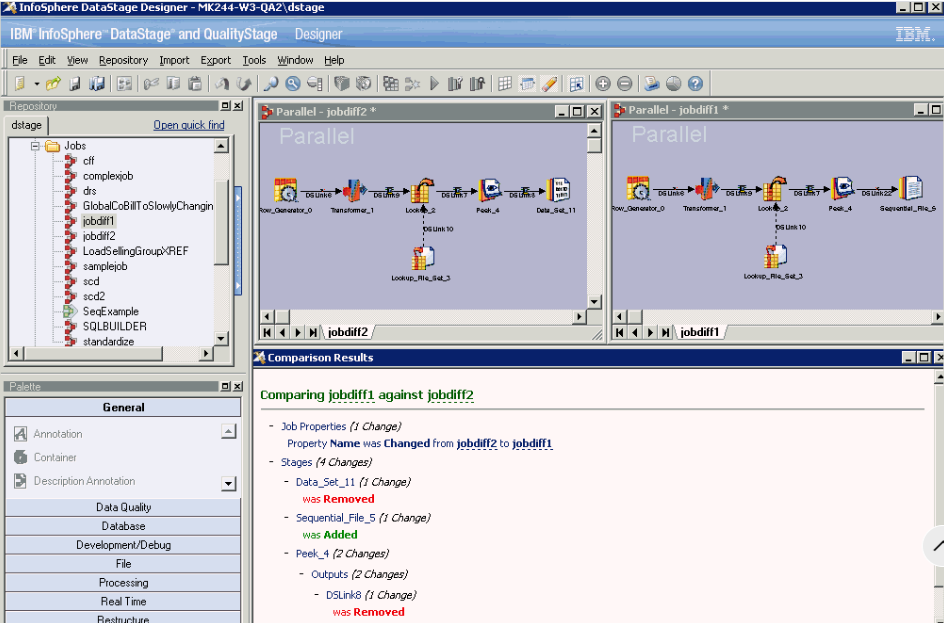
Screenshots:
4. SQL Server Integration Services (SSIS):

SQL Server Integration Services (SSIS) is a data warehousing implement utilized for data extraction, loading, transformations. This tool is used to carry out a wide variety of transformation and integration duties. It consists of the graphical equipment and window wizard’s workflow capabilities which include sending email messages, FTP operations, data sources. This tool is used in data migration.
Key Features:
- This is a combination of Connections Managers, Packages, and project parameters (optional).
- This tool specially used to carry out Data Integration and workflow.
- This tool is utilized to cumulate the data from more than one data source to generate a single structure in a cumulated view.
- Azure Feature Pack includes a connection manager, source, and destination to move data to and from Azure Data Lake Store.
- SQL Server Data Tools (SSDT) use SSIS Designer for Visual Studio 2015 to create, maintain, and run packages that target SQL Server 2016 / 2014, or SQL Server 2012.
- Validate XML documents and get error output by way of permitting the validation information property of the XML Task.
- SSIS tool is less expensive than most of the other tools. It can resist other base products, manageability, business intelligence, and so on.
- It could be without difficulty accessed in order that the data warehouse can be used effectively and efficiently.
- This tool has a built-in scripting environment to be had for writing code.
Screenshots:
5. DMExpress

DMX-h is high-performance data integration software that turns Hadoop into a better and characteristic wealthy ETL solution, allowing customers to maximize the benefits of MapReduce without compromising on skills, ease of use, and typical use cases of conventional ETL tools.
Key features:
- Transforming and distributing application data for analytics with pace, performance and a flexible “design once, setup anywhere” method.
- Promises up to 10x quicker performance except manual coding or tuning.
- combine all data throughout business enterprise RDBMS, Mainframe, NoSQL, the may want to, Hadoop and more will connect ETL.
- Move masses of tables at once.
- Import data from a source such as Db2, Oracle, SQL Server, Teradata, Netezza and RedShift and indite them to databases like SQL Server or Postgres.
- This tool is a data integration tool with wise execution.
- At once feed data to your preferred facts visualization tool.
Screenshots:
6. Pentaho Data Integration

Pentaho Data Integration (PDI) is an extract, transform, and load (ETL) solution that makes use of an innovative metadata-driven approach. ETL skills that facilitate the manner of capturing, cleansing, and storing data using a uniform and consistent layout that is available and relevant to end-users and IoT technologies. Pentaho is a one forestall answer for all business analytics needs.
Key features:
- Pentaho Data Integration is a full-featured open source ETL solution that permits you to satisfy the requirements.
- This tool is 100% Java with cross-platform support for Windows, Linux, and Macintosh.
- Clean to apply graphical designer with over 100 out-of-the-box mapping objects which including inputs, transforms, and outputs.
- This depends on potent visualizations that permit users to engage with their data, zooming in and optically discerning in detail consequential statistics.
- Data Integration together with the facility to leverage genuine-time ETL as a data source for Pentaho Reporting.
- Schedule transformations and jobs to run at particular times.
- It is simple plug-in architecture for integrating your own custom extensions
- A different combination of data integration and analytical processing, the first BI tool to market direct reporting for NoSQL, a wide variety of reporting solutions.
Screenshots:
7. Talend

Talend is a famous open-source data integration platform. This Data Management Platform is a user-based subscription software with tremendous data integration (ETL, ELT) and data management capabilities. The services and software required for enterprise application integration, data integration or management, Big Data, cloud storage and improving data quality are offered by Talend. This tool gives robust data integration tools for performing ETL processes.
Key Features:
- Talend Data Fabric presents an entire suite of apps that connect all your data, irrespective of the source or destination.
- This tool additionally offers Open Studio, which is an open-source free tool used extensively for Data Integration and Big Data.
- This tool is a graphical user interface utilizing which you can simply map data between the source and target areas.
- Automated data integration process synchronizes the data and eases actual time and periodic reporting, which in any other case is time eating if accomplished manually.
- Data that is integrated from several sources mature and amends over time, Which ineluctably avails in better data quality.
- This tool implements meets all the desiderata of the businesses under a common roof.
Screenshots:
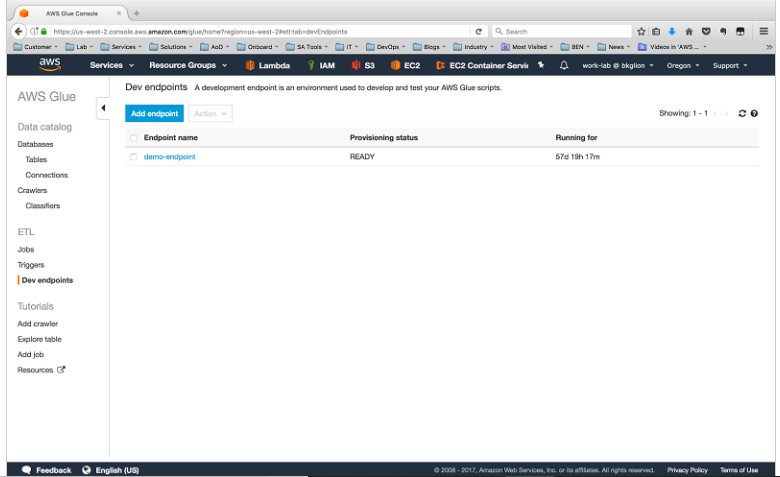
8. AWS Glue

WS Glue is a totally controlled ETL service that you can utilize to catalog your data, clean it, enrich it, and move it reliably between data stores. This tool can minimize cost, complexity, and creating ETL jobs. AWS Glue is serverless, so there is no infrastructure to setup or control. You pay best for the resources consumed while your jobs are running.
Key Features:
- This is a “Serverless” service. User does not want to provision or control any resources/services.
- Data Catalog is your continual metadata keep for all your data, irrespective of where they are located.
- AWS Glue aid for Python 3.6 in Python shell jobs and connecting directly to AWS Glue via a virtual private cloud.
- You may run crawlers on a schedule, on-demand, or trigger them totally on an event to ensure that your metadata is up to date.
- Automatically detecting modifications in your DB schema and adjusting the service in order to match them.
- AWS Glue avails smooth and prepares your data for evaluation by means of offering a Machine Learning Transform referred to as Find Matches for deduplication and locating matching records.
- In case you choose to interactively expand your ETL code, AWS Glue affords development endpoints with a view to edit, debug, and test the code it generates for you.
Screenshots:
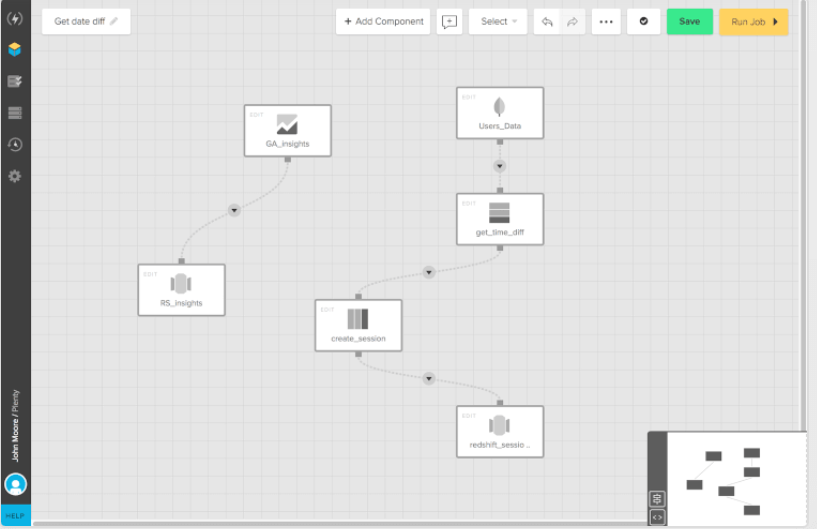
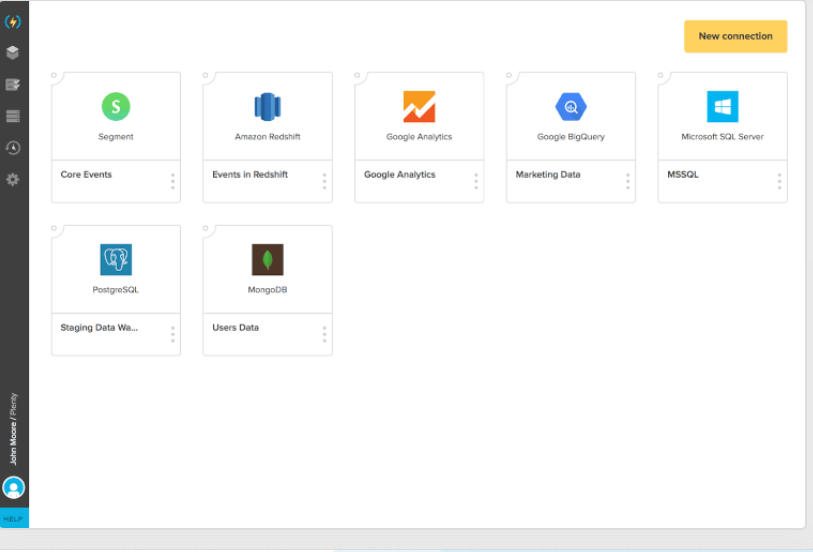
9. Xplenty
 Xplenty is a cloud-based ETL and Extract, Load, Transfer (ELT) data integration platform that facilely amalgamates multiple data sources Xplenty is the capacity to combine with a selection of sources. The tool has connectors for diverse data sources and SaaS applications. It additionally affords an intuitive graphical interface. This tool Creates simple, visualized data pipelines to your data warehouse or data lake. One of the best of these platforms is Xplenty.
Xplenty is a cloud-based ETL and Extract, Load, Transfer (ELT) data integration platform that facilely amalgamates multiple data sources Xplenty is the capacity to combine with a selection of sources. The tool has connectors for diverse data sources and SaaS applications. It additionally affords an intuitive graphical interface. This tool Creates simple, visualized data pipelines to your data warehouse or data lake. One of the best of these platforms is Xplenty.
Key Features:
- A consummate toolkit for building data pipelines. Implement an ETL, ELT or a replication solution utilizing an intuitive graphic interface.
- Xplenty to your data solution stack effortlessly. Use our API for stronger flexibility and customization.
- Xplenty avails businesses layout and executes complicated data pipelines.
- This tool deals with ops – deployments, monitoring, scheduling, security, and maintenance.
- This platform affords a simple, intuitive visual interface for building data pipelines between many sources and destinations.
- The support for this tool is so active, Data integration can be complicated due to the fact you have to take care of the scale, complicated file formats, connectivity, API access and more.
Screenshots:
 10. Alooma
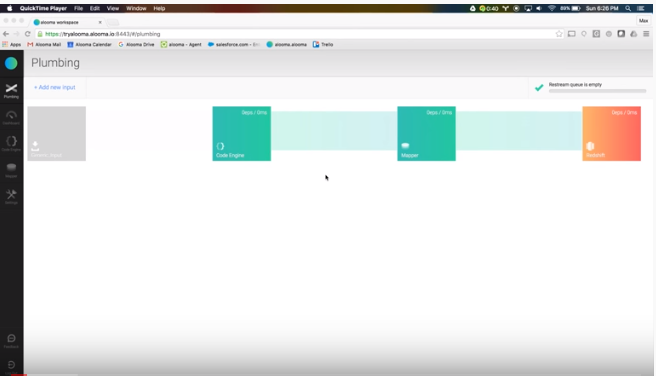
10. Alooma

Alooma is a scalable, secure, enterprise ETL platform in the cloud. It is cloud-based, completely managed, and helps batch in addition to actual-time data ingestion. Alooma’s enterprise platform provides a format-agnostic, streaming data pipeline to simplify and allow real-time data processing, transformation, analytics, and business intelligence. Alooma goes beyond ETL to carry together all of your data.
Key Features:
- Alooma affords data teams a modern, scalable cloud-based ETL solution, bringing collectively records from any data source into any data warehouse, all in authentic time.
- This tool can migrate all your data into Amazon S3, where you can leverage industry-standard AI or ML capabilities.
- Easy, fast, secure, and fortified way to migrate your data from on-premise storage to the cloud.
- The tool has built-in data cleansing features to supercharge your data ingestion efforts.
- Supports native and custom integrations with enterprise scalability and zero latency.
- You could create or update your statistics map across your complete pipeline!
- Alooma can manage hundreds of data sources and destinations. Move your data with the confidence of best practices, built right in.
- Let’s integrate your data from multiple sources to a single destination with minimal planning and effort.
Screenshots:
Please let us know if you have any queries regarding any of the above ETL Testing Tools. Always happy to help.
All the Best!


