XPath for Web Scraping with R – Detailed Step by Step Guide
We have already learned about Web Scraping Technology in our previous post Web Scraping Using Beautiful Soup in Python. In addition to that, a learner/developer might also be interested in fetching nodes/elements from the HTML or XML document using XPaths.
XPath For Web Scraping with R:
This article essentially elaborates on XPath and explains how to use XPath for web scraping with R Programming language.
What is XPath
XPath stands for XML Path Language. It is a query language to extract nodes from HTML or XML documents.
Required Tools and Knowledge
- R Programming Language
- XML Package
- HTML/XML
How to get XPath in Mozilla Firefox Browser
Let us see how to find out XPath of any element on www.opencodez.com using the Mozilla Firefox browser. We want to identify the XPath for the heading text of the first article on the home page. When we right-click on the highlighted element, we can find the Inspect Element option. A screenshot is attached below.
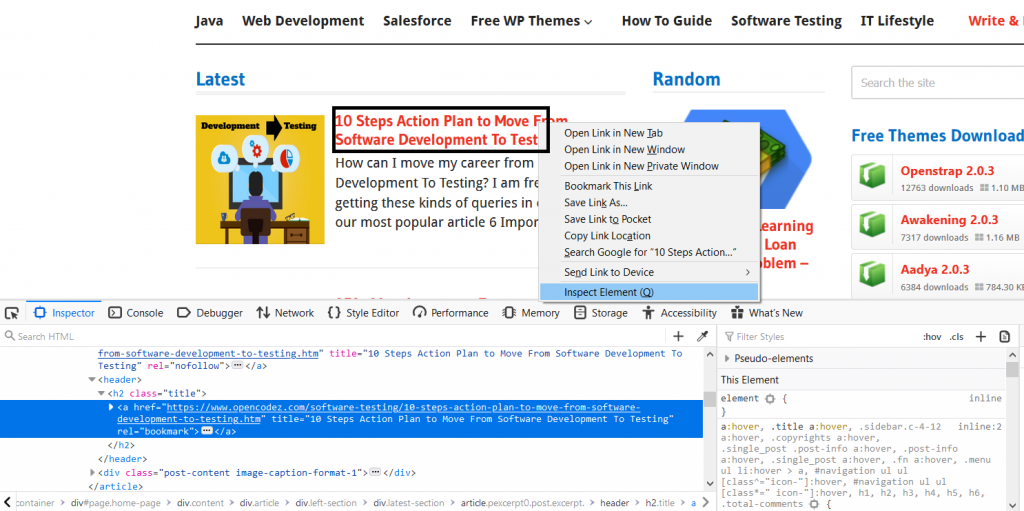
Observing the element HTML Code, we can identify that our target text is contained in the ‘a’ tag. (highlighted in blue at the lower section of the screenshot). Next, we need to right-click on the blue highlight. Another box with several options opens up. Click on “Copy” which will show us new options. There will be an XPath option also. Click on that. Have a look at it in the below screenshot.
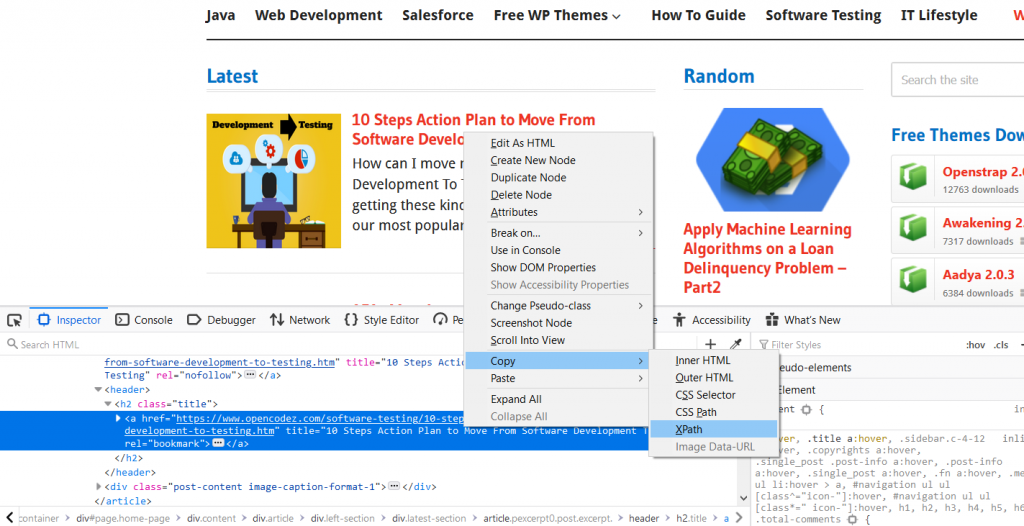
Copy this XPath in any text file and check how does it look like. The XPath copied is /html/body/div[2]/div/div/div/div[1]/div[1]/article[1]/header/h2/a.
Absolute and Relative XPath
Absolute Path –
The XPath provided above is called the absolute path. It starts with ‘/’ and traverses from the root node to the target node. Let us take a look if this XPath is correctly identified by Firefox. The set of commands is provided below.
|
1 2 3 4 5 |
library(XML) url <- "https://www.opencodez.com/" source <- readLines(url, encoding = "UTF-8") parsed_doc <- htmlParse(source, encoding = "UTF-8") xpathSApply(parsed_doc, path = '/html/body/div[2]/div/div/div/div[1]/div[1]/article[1]/header/h2/a', xmlValue) |
When we run the commands in R Studio, we find that the result is a NULL. The corrected XPath is provided below.
|
1 |
xpathSApply(parsed_doc, path = '/html/body/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/article[1]/header/h2/a', xmlValue) |
xpathSApply is a function available in the XML library in R. xmlValue is the argument we need to pass so that we get the value of the target node. In our case its the heading of the article.
Relative Path –
We can create a short and concise path to our target node by using ‘//’ to jump between nodes. For example, the above absolute path can also be written as //h2/a. This path also points to our target ‘a’ tag. There can be other ways to represent this path as well. Now let us take a look at the command to extract the heading text.
|
1 |
xpathSApply(doc = parsed_doc, path ="//h2/a", xmlValue)[1] |
The output is a character vector with 22 values in it. A snapshot of the output is provided below. Hence we need to fetch the first text by using [1] in the command.

Other ways to represent XPaths
Wildcard Operator * –
The wildcard operator * matches any (single) node with an arbitrary name at its position. In our case, a wildcard operated XPath will look like below.
|
1 |
(xpathSApply(doc = parsed_doc, path ="//h2/*", xmlValue))[1] |
Wildcard Operator . and .. –
Here we are going to explain two more operators ‘.’ and ‘..’ and its usage in the XPath command. The . operator selects the current nodes (or self-axis) in a selected node-set. The .. operator selects the node one level up the hierarchy from the current node. Let us all try this for ourselves. Do share the commands or scenarios in the comments where any difficulty is faced.
Numerical Predicate –
Some predicates or functions can also be used to pinpoint nodes using position, last or count in the command. Our target node XPath will change in the below manner.
|
1 2 3 4 5 6 7 8 |
#Position xpathSApply(doc = parsed_doc, path ="//h2[position()=1]", xmlValue)[1] #Last xpathSApply(doc = parsed_doc, path ="//h2[last()]", xmlValue)[1] #Count xpathSApply(parsed_doc,"//h2[count(.//a)>0]", xmlValue)[1] |
Position –
We are trying to locate all the h2 tags which have got the first position in the node tree structure. As explained earlier, this will generate a character of 22 values. Our ‘position’ command extracts the first value because of [1] in the command.
Last –
Similar to the above, all the h2 tags which are last in the tree structure will be extracted. The first value can be fetched using [1]. We can experiment to fetch other article headings by changing the value inside the box bracket.
Count –
The command looks a bit scary!! But don’t be. It simply extracts all the h2 nodes which have got ‘a’ tag present. If we observe the ‘h2’ tags in the HTML code, we will notice that all the ‘h2’ tags do have a child tag ‘a’ and so this command is the same as the one we saw in the relative path section. With the presence of [1], it allows us to fetch the first article heading text.
If you were facing issues working with the . operator command as suggested earlier, this example should provide you with some understanding.
Text Predicate –
We can also locate some nodes with the manipulation of text related predicates. Explaining this will require a change in our target node. Text predicates help us in cases where we want to extract text which contains a specific word or characters or let say has a length condition on characters. Let us see some commands.
Contains –
|
1 2 |
library(stringr) xpathSApply(parsed_doc,"//a[contains(text(), '10')]", xmlValue) |
The above command will throw a list of headings that have got 10 in its text. The output snapshot is provided below.

Starts-with –
When we want to fetch text of any attribute which starts with a particular string pattern, we can use starts-with predicate in the command. Attributes in any tag are addressed using ‘@’ symbol. Have a look at the command. Do try to understand the output for this and let us know if you face any difficulty.
|
1 |
xpathSApply(parsed_doc,"//a[starts-with(./@title, '10')]", xmlValue) |
XPath Node Relations –
A very interesting way to prepare XPaths is by understanding the tree analogy of the nodes in the HTML code structure. As is usual in describing tree-structured data formats, we employ notation based on family relationships (child, parent, grandparent, …) to describe the between-node relations. The construction of a proper XPath statement that employs this feature follows the pattern node1/relation::node2, where node2 has a specific relation to node1. Let us see some examples.
Ancestor –
|
1 |
xpathSApply(parsed_doc,"//a/ancestor::article", xmlValue) |
The command locates and fetches all the article tags which are an ancestor to a tag.
Child –
|
1 |
xpathSApply(parsed_doc,"//div[position()=1]/child::article", xmlValue) |
The command locates and fetches all article tags which is a child of div tag in the first position in the tree structure.
There are many other such relations that we can utilize like a sibling, preceding-sibling, descendant, following, etc.
Conclusion –
I hope you found this step by step detailed guide on XPath for Web Scraping with R useful. There are many more options with which we can create XPaths apart from the ones we have explained in this article.
It is encouraged that the reader tries these commands themselves to practice and gain a deeper understanding of a faster smoother experience with Web Scraping. Do comment if you want to understand any specific XPath command, if you face any error or you want to know about any other concept related to Web Scraping.
Happy Learning!!!



Fantastic howto. Using chrome headless to dump page, then xml2 R package to parse, with ‘inspect element’ in firefox upfront. Essentially using read_html, xml_find_all and xml_text to arrive at character vectors containing the data