
Web Scraping Using Beautiful Soup:
In this article, we will see what is Web Scraping? why Web Scraping? Different ways for web scraping and step by step tutorial of Web Scraping using Beautiful Soup.
What is Web Scraping?
The method of extracting data from websites is called web scraping. It is also called web data extraction or web harvesting. This technique is not more than 3 decades old.
Why Web Scraping?
The purpose of web scraping is to fetch data from any website thereby saving a huge amount of manual labor in collecting data/information. For example, you can collect all the reviews of a movie from the IMDB website. Thereafter you can perform text analytics to gain insights about the movie from the huge corpus of reviews collected.
Ways to do Web Scraping
There are several chargeable/free web scraping tools available in the market today.
We can also write our own code for performing scraping using python with requests and Beautiful Soup. Another package named Scrapy can also be used for the same. In this article, we will learn how to use Beautiful Soup for web scraping.
Required tools and knowledge
- Python
- HTML
- Jupyter Notebook
- Requests
- BeautifulSoup4
- Pandas
There are innumerable websites available that provide a lot of numeric or text information. Before starting with a scraping code, we need to identify what data we are going to scrape from the website. That will help us aim at those particular sections of the web page while coding.
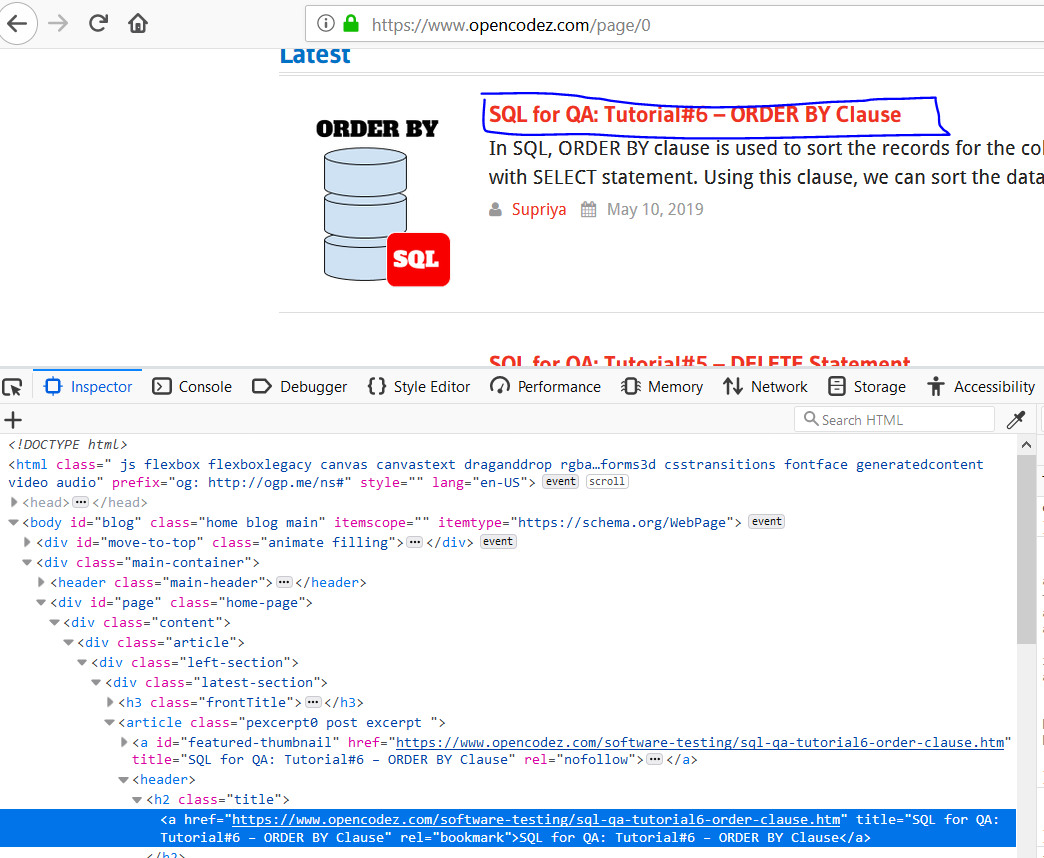
For example, opencodez.com provides us with several posts on various technologies. I want to create an excel containing the title of all the articles written, the short paragraph, its author, date, and the web link to those articles. The below screenshot shows the sections I need to target in my code.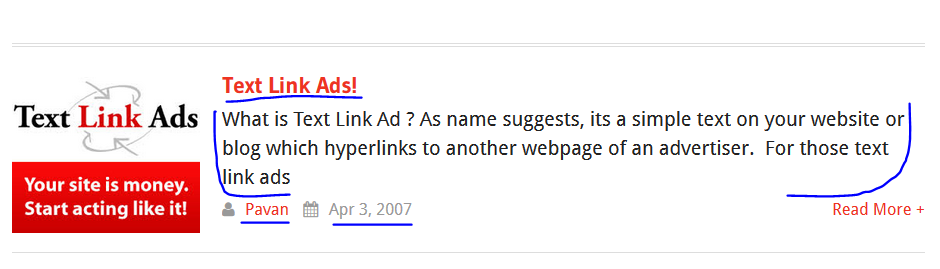
Understanding the website structure (CSS/HTML)
Every website has its own structure and is created using HTML along with CSS and JavaScript. HTML comprises of tags that we need to understand. We can use w3schools to get some basic knowledge of HTML/CSS. It is helpful if we understand the structure of our target website. Very lucid information related to several HTML tags is provided in the link https://www.elated.com/first-10-html-tags/
When we hit Inspect element after right-clicking on any section of our website we can see its structure. See a screenshot provided below for the same article section as provided in the above snapshot for ease of understanding.
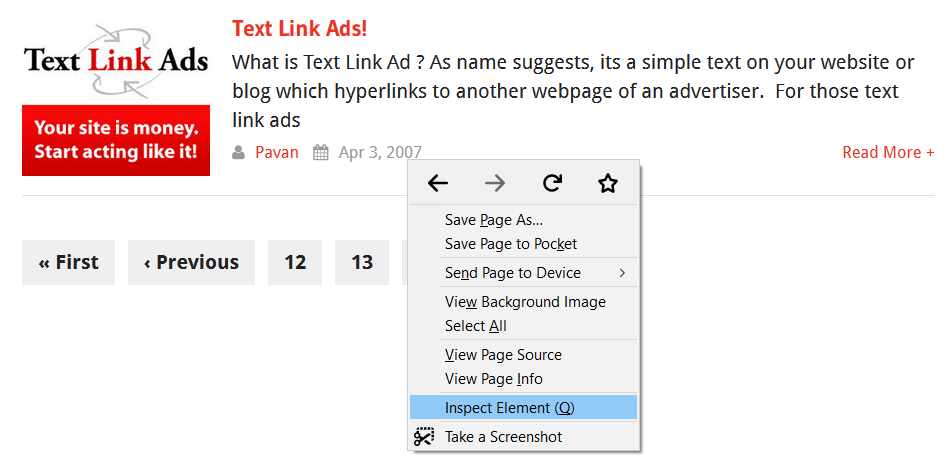

Once the Inspect Element is hit, the details open up as follows:
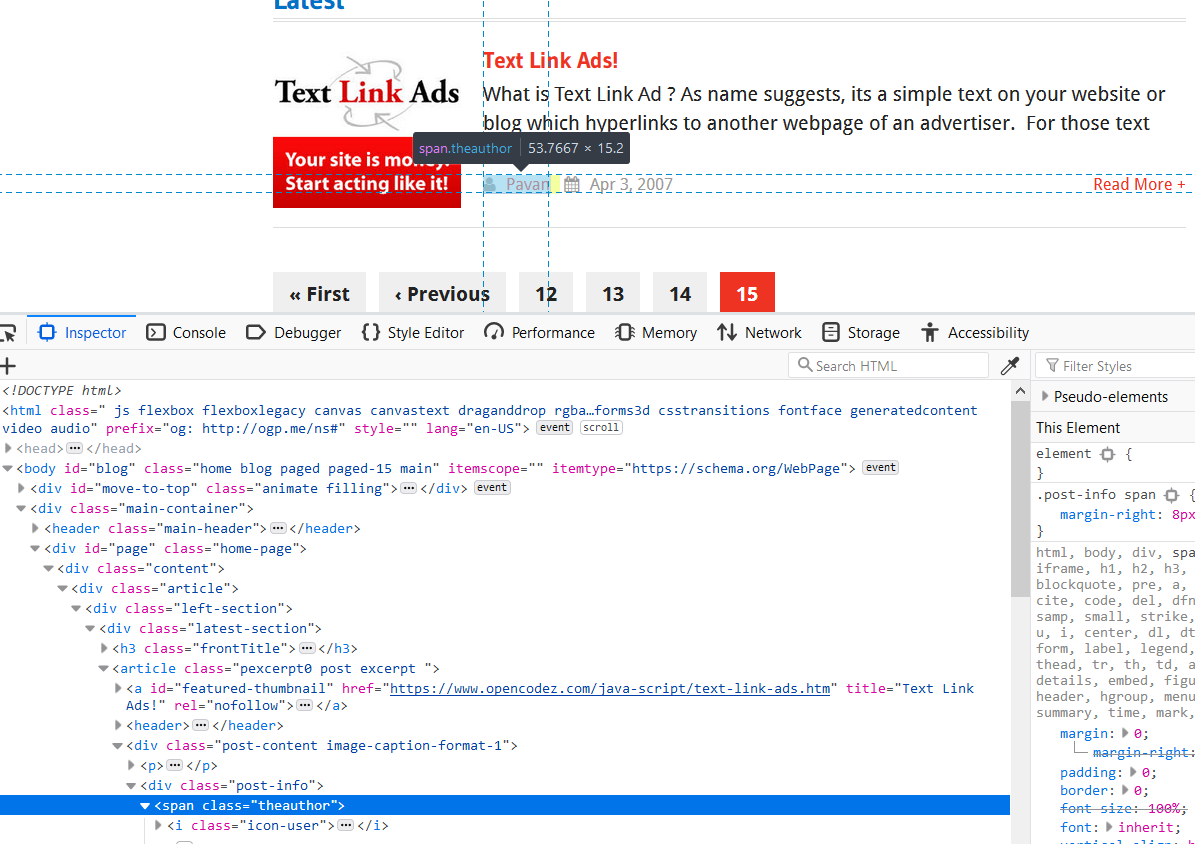

Observe the section named âPavanâ and its element tag span in the snapshot.
Understanding pagination
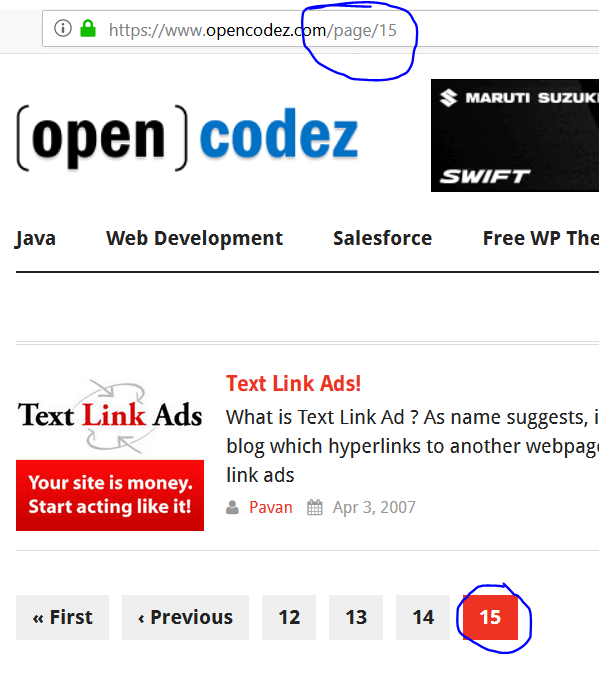
The opencodez website comprises of pagination i.e. we have several pages to scrape to generate the collection of all the articles. The first screenshot of the homepage below shows the web address and the pagination at the bottom. If we hit the xlastx button we can see that the address changes as highlighted in the second screenshot and points to page number 15.
You can observe the web link at the top consists of x/page/15x to mark the page address. We will apply some logic to scrape this website up to page 15.
A snapshot of the home page is shown below.
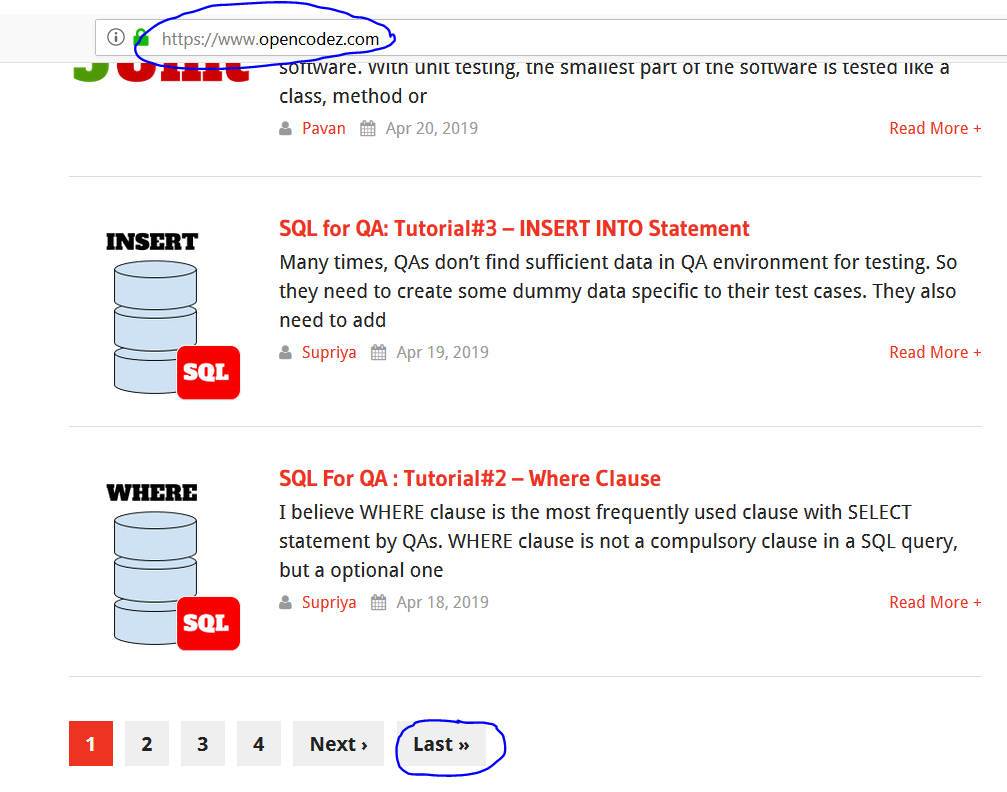

Once we hit the LAST button the URL changes as in the below snapshot showing us the web link in terms of page number. It is 15 in our case.
Scraping the first page to begin
If we change the page number on the address space you will be able to see various pages from 0 to 15. We will begin scraping the first page which is https://www.opencodez.com/page/0.
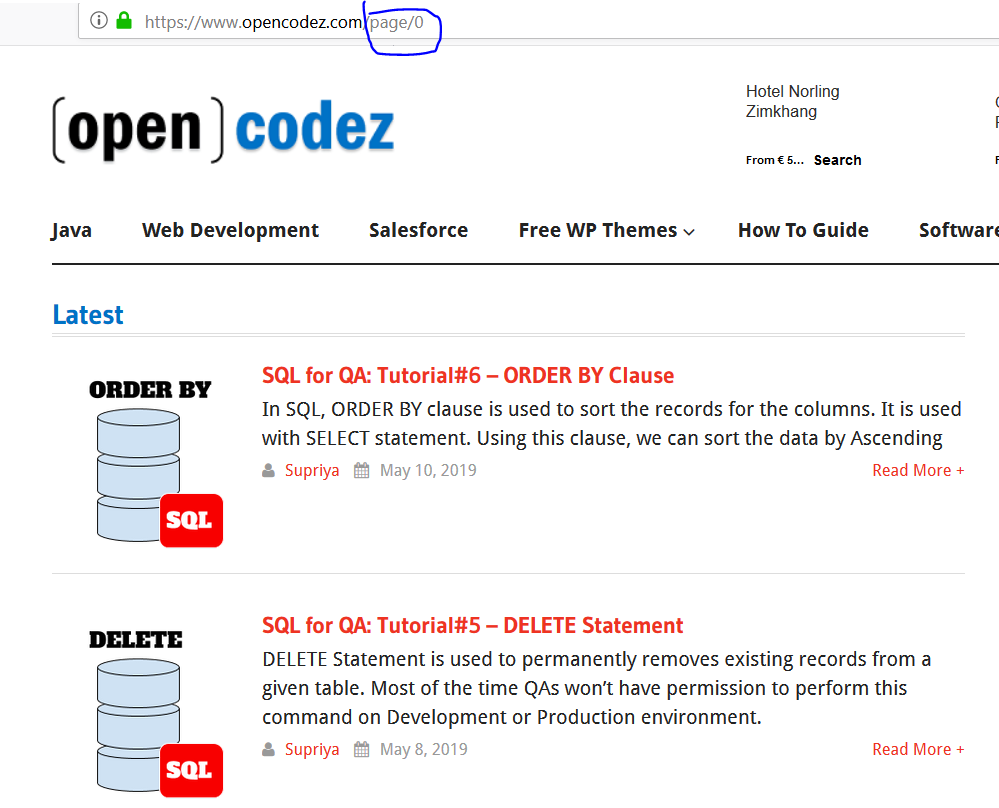

As the first step, we will send a request to the URL and store its response in a variable named response. This will send all the web code as a response.
url= https://www.opencodez.com/page/0 response= requests.get(url)
Then we have to parse the HTML response content with html.parser. Let us name it as soup.
soup = BeautifulSoup(response.content,"html.parser")
Now let us see how the response looks like.

We will use the prettify function to organize it. See how the output is organized after using this command.
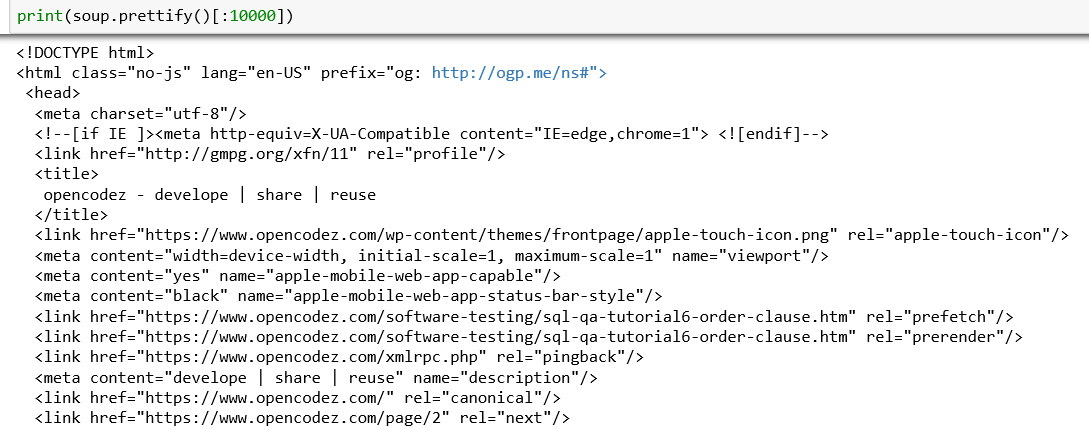

Let us observe the page section from where we have to pull details. If we inspect its element by the right-click method I told earlier, we see the details of href and title of any article lies within the tag h2 with a class named title.

The HTML code for the article title and its link is in the blue box above.
We will pull it all by the following command.
soup_title= soup.findAll("h2",{"class":"title"})
len(soup_title)
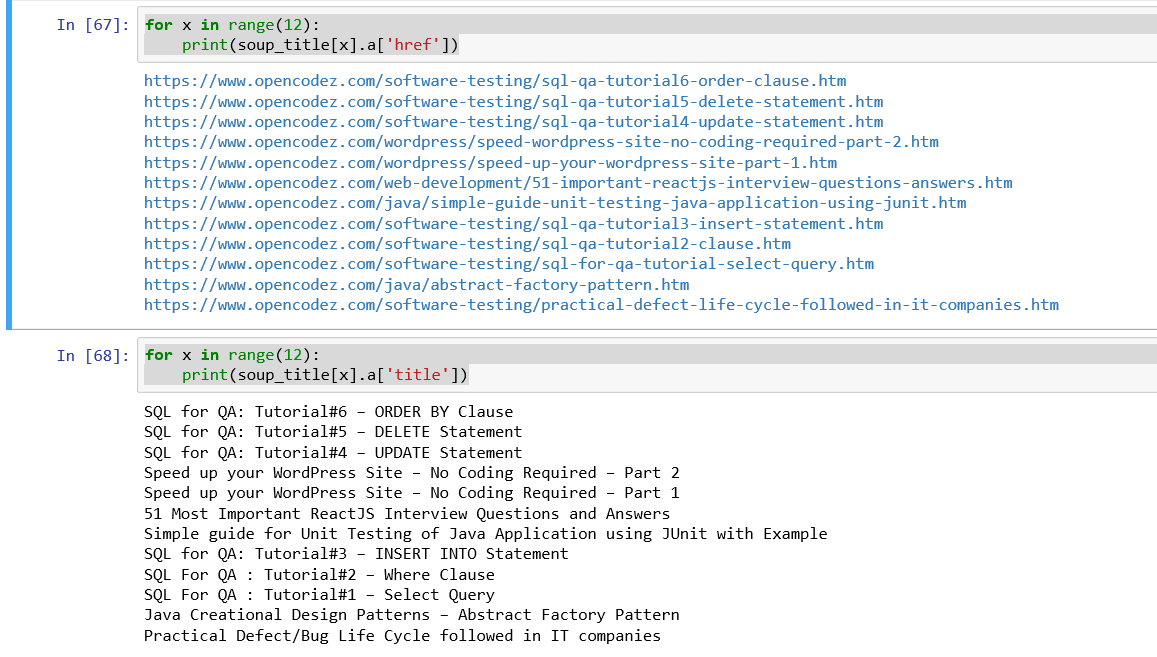
A list of 12 values will be pulled out. From these we will pull the titles and hrefs of all the articles posted by using the command as follows.
for x in range(12): print(soup_title[x].a['href']) for x in range(12): print(soup_title[x].a['title'])

To collect a short description of posts, author, and date, we need to aim at the div tag containing the class named xpost-content image-caption-format-1x.
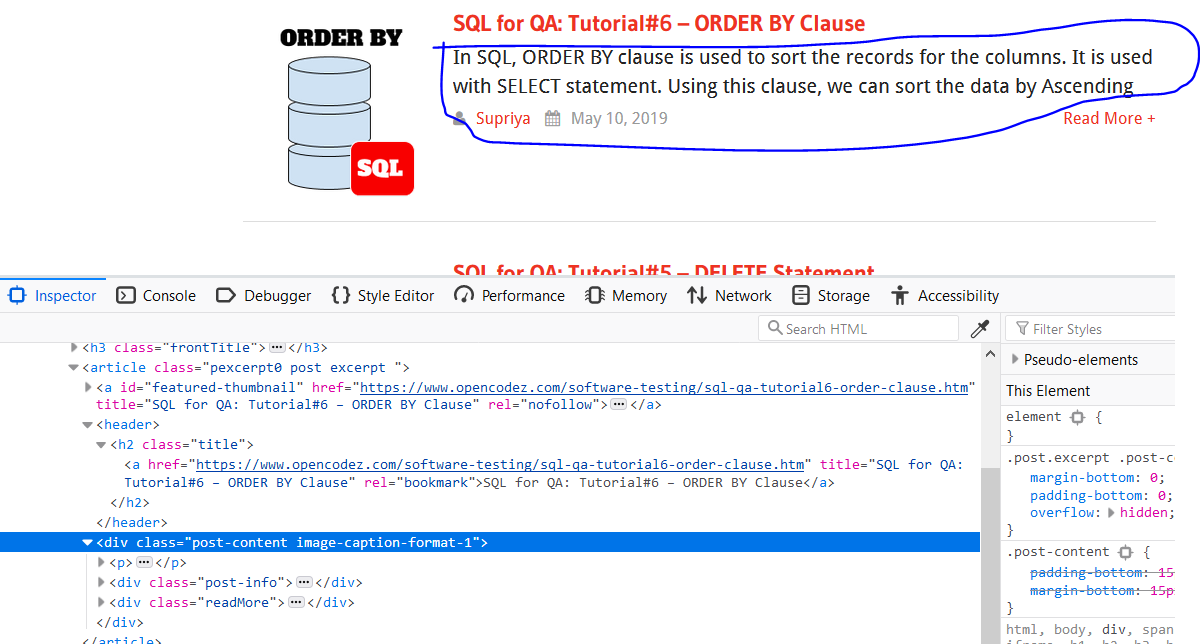

The commands would be as follows:
soup_para= soup.findAll("div",{"class":"post-content image-caption-format-1"})
for x in range(12):
print((soup_para[x]).p.text.strip())
for x in range(12):
print(soup_para[x].a.text)
soup_date= soup.findAll("span",{"class","thetime"})
for x in range(12):
print(soup_date[x].text)
Further explanation of code
| Once these are collected for the first page we need to apply a loop to pull these details from the other pages of pagination. We will be using a for loop and append variable values one after the other. A variable page_number is used and incremented to create the next webpage address to be fed as an argument in the function. After the successful procurement of all the data from every page, we create a data frame with all the variables and use the pandasx package to store it in a CSV. |
The Complete Code
#importing requests, BeautifulSoup, pandas, csv
import bs4
from bs4 import BeautifulSoup
import requests
import pandas
from pandas import DataFrame
import csv
#command to create a structure of csv file in which we will populate our scraped data
with open('Opencodez_Articles.csv', mode='w') as csv_file:
fieldnames = ['Link', 'Title', 'Para', 'Author', 'Date']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
#Creatibg empty lists of variables
article_link = []
article_title = []
article_para = []
article_author = []
article_date = []
#Defining the opencodezscraping function
def opencodezscraping(webpage, page_number):
next_page = webpage + str(page_number)
response= requests.get(str(next_page))
soup = BeautifulSoup(response.content,"html.parser")
soup_title= soup.findAll("h2",{"class":"title"})
soup_para= soup.findAll("div",{"class":"post-content image-caption-format-1"})
soup_date= soup.findAll("span",{"class":"thetime"})
for x in range(len(soup_title)):
article_author.append(soup_para[x].a.text.strip())
article_date.append(soup_date[x].text.strip())
article_link.append(soup_title[x].a['href'])
article_title.append(soup_title[x].a['title'])
article_para.append(soup_para[x].p.text.strip())
#Generating the next page url
if page_number x16:
page_number = page_number + 1
opencodezscraping(webpage, page_number)
#calling the function with relevant parameters
opencodezscraping('https://www.opencodez.com/page/', 0)
#creating the data frame and populating its data into the csv file
data = { 'Article_Link': article_link, 'Article_Title':article_title, 'Article_Para':article_para, 'Article_Author':article_author, 'Article_Date':article_date}
df = DataFrame(data, columns = ['Article_Link','Article_Title','Article_Para','Article_Author','Article_Date'])
df.to_csv(r'C:\Users\scien\Desktop\Machine Learning\OpenCodez_Articles.csv')
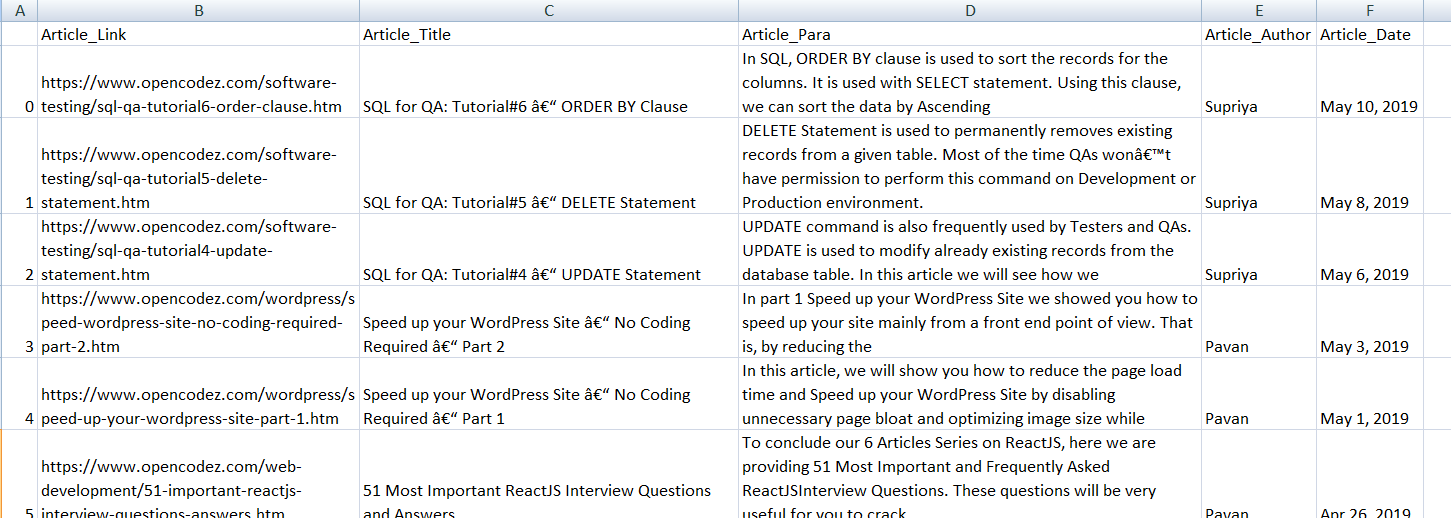
Output file
A csv file snapshot is provided.

Using output in various ways
Now we have our desired CSV. We can do some exploratory data analysis on this data to see for example the number of articles written by each author or to make a yearly analysis on the number of articles. We can also create a word cloud from the corpus of a brief description column to see the most used words in the posts. These will be dealt with in the next post.
Word of caution for web scraping
The legality of this practice is not well defined, however. Websites usually describe in their terms of use and in their robots.txt file if they allow scrapers or not. So please be careful not to tread in restricted territories or not to hit the URL with a huge number of requests in a short duration causing issues with the website itself 🙂
I hope you found it useful.
In the next article, we will see what we can do with scrapped data. Please stay tuned!
Web Scraping Using Beautiful Soup Word Cloud x Part 2
x
x